
Нейросеть помогает распознать интервью

Текст: Даня Шевель
Илл. на обл.: ИИ Gemini под управлением автора
Так получилось, что я предложил автоматизировать расшифровку аудиоинтервью в текст, хотя никогда этим не занимался… Порой люди сталкиваются с подобными вызовами, и им приходится как-то справляться с ними. Я советую в таких ситуациях следовать заветам Олега Куваева [Олег Игоревич Куваев внесен Минюстом в реестр иноагентов. Если вы не достигли 18+, не читайте эту цитату! — Прим. ред.]: «Когда что-то не умеешь — просто сядь, возьми и сделай, у тебя ведь голова не деревяшка — может думать...»
Голосовой ввод у нас существует? — Да.
Голосовые в мессенджерах расшифровываются? — Да.
Умные колонки и прочие штуки работают? — Да.
Тогда и интервью можно! В чём проблема?
Оказалось, всё не так уж просто...
Итак, есть аудио, надо сделать текст. Как?
Конечно, самое очевидное — это послушать и записать его своими же руками. Но: если это полтора часа разговоров, то даже просто «послушать» — займёт те же самые полтора часа. Что уж говорить про «набрать», когда не всякий владеет слепым десятипальцевым! А мы же еще хотим автоматизацию, так? Машины будут работать, а мы — плевать в потолок. Мы к этому уже близко, да? Наверное, что-то с нейросетями нам подойдёт. Тогда с чего нам следует начать? Изучить, что используют в похожих ситуациях и какие вообще существуют нейросети для таких задач!
Я, конечно, не был готов тратить деньги на случайный эксперимент, да и в целом тяготею к свободному программному обеспечению, если это возможно. (Например, этот текст я печатаю в libre office на Linux.) Так что платные опции я даже не собирался рассматривать. Беглый поиск подсказал, что массовый стандарт и точка отсчёта в области распознавания речи — это Whisper от OpenAI (да, те самые, ещё ChatGPT сделали).
Установить Whisper — дело несложное, инструкции легко найти в интернете. Здесь не хабр, статья больше вводная, чем техническая, поэтому сразу к делу. Аудиофайлы на вход — текст на выход (в формате .txt), и важно указать язык, который Whisper будет пытаться понять.
Сперва я сам записал звук для теста. Хороший микрофон, спокойная речь, один человек, внешняя звуковая карта:
Читаю свой перевод стихотворения, которое написал китайский поэт Цзин Бо (подробнее об авторе — в этой статье).
Ветер — сквозь пальцы мои:
Я ощущаю его
И сжимаю ладонь.
В ветре — запах цветов;
В ветре — пение птиц;
В ветре — песни твои...
Раскрываю ладонь —
Ты дух свободы, лети,
Ветер, сквозь пальцы мои.
Распозналось очень хорошо. Это было заметно ещё в командной строке:

Следующее аудио — часть от настоящего интервью, которое берет главный редактор этого Музея. Обычный диктофон на телефоне, свободная беседа (живая речь) в общественном месте:
И тут уже результат получился заметно хуже.
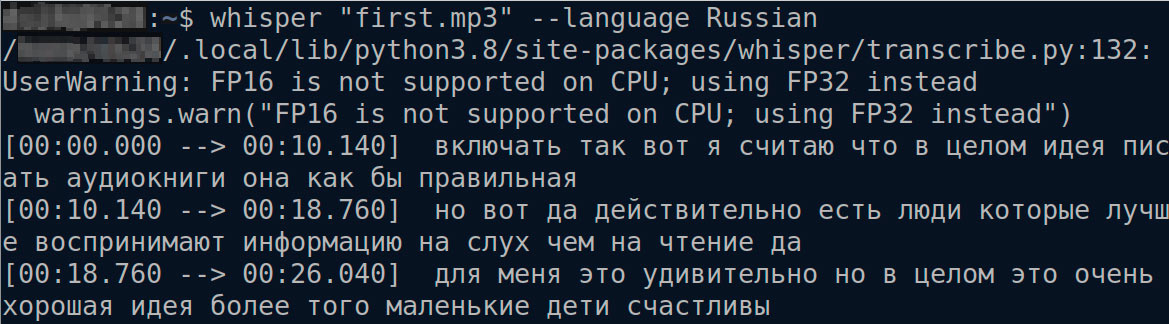
Стало понятно, что потребуется дополнительная обработка — текст на выходе совершенно не структурирован:

И снова нам надо сперва понять, а есть ли нейросети, которые смогут отформатировать текст? Вроде бы есть, но с ними не всё так просто, тем более — под русский язык. И задача у них не из лёгких: нужно прочесть сплошной текст, найти, где начинается и заканчивается каждое предложение, а значит, и понять, какое значение у каждого слова и как оно связано с другими словами.
Возьмём тот же пример фрагмента из интервью:
«включать так вот я считаю что в целом идея писать аудиокниги она как бы правильная но вот да действительно есть люди которые лучше воспринимают информацию на слух чем на чтение для меня это удивительно но в целом это очень хорошая идея более того маленькие дети счастливы»
«Включать — так. Вот. Я считаю, что в целом идея — писать аудиокниги...» Странный, но возможный вариант, ведь так?..
Поэтому неудивительно, что простых вариантов не нашлось. Я перепробовал разные идеи: скрипты на python, загадочные библиотеки, но ничто не заработало так, как заработал Whisper. Тогда я решил проверить, что дадут генеративные нейросети: ChatGPT, DeepSeek, Mistral, Gemini и т.п.
Я взял файлик с текстом и отдал каждой из нейросетей. Если подобрать промт — они могут в целом весьма неплохо справиться с задачей. На одном из аудиофайлов я формулировал задачу так:
«Вот текст из интервью, получен обработкой аудиофайла через Whisper. Сейчас нужно обработать этот файл так: собрать из него цельный текст, расставив знаки препинания. Не нужно переписывать своими словами. Короткие фразы по возможности нужно объединять в целые предложения. Можно разбивать текст на абзацы. Над финальным результатом будет работать человек, поэтому все слова из исходного файла должны быть на месте — человек будет слушать аудио и форматировать текст».
Оказалось, нейросети могут придумывать отсебятину. Иногда пытаются переписать текст (в том числе — выкинув какие-то фрагменты). А порой — могут бесконечно уточнять задачу и придумывать отговорки, почему и вовсе её не выполнят.
Например, одна из нейросетей «нашла» 70 тысяч символов в файле, где их было только 17 тысяч:

Или вот — рассмотрим пример «переписывания» текста.
Было: «у издательства есть еще одна проверка выборочная и у нас есть человек например для эксмо мы еще сами выборочно то есть у нас еще отдельный человек тоже с логическим управлением который выборочно проверяет там все эти моменты и только после этого мы уже пересчитываем правильные форматы и как говорится сдаем но либо выносим правки нет правки мы вносим конечно на этапе вот понятно когда звукорежиссер чистящий привет всегда там правки на это по 8 справок иногда там по 100 правок там на книгу по всякому бывает»
Стало: «Потом — проверка издательства, иногда ещё одна выборочная проверка у нас. После этого пересчитываем форматы, сдаём. Правок может быть 8, может 100 — как повезёт.»
Как видим, эта способность нейросети может быть удобной, но с другой стороны — в равной степени может сильно исказить идею или стилевые нюансы речи. А как нам узнать, не написала ли нейросеть нам какой-нибудь ерунды в расшифровку? Ещё одну нейросеть позвать? Думаю, что тут лучше будет уже обратиться к человеку… Эх, если бы можно было положиться на нейросети, как мы полагаемся на людей!..
Еще один нюанс: как видно из последнего рисунка («текст на выходе»), при расшифровке и обработке текста не происходит деления текста «по голосам», т.е. по количеству участников — диалога или, допустим, конференции. И если бы мы задались целью решить вопрос технически, перед расшифровкой потребовалось бы: предварительно пройтись по файлу еще одной программой, чтобы определить таймкоды говорящих, потом — нарезать аудио на эти кусочки (временные отрезки), и только после этого — приступить к расшифровке. Ах да! И еще стояла бы задача собрать итоговые расшифрованные реплики и монологи в единый полноценный текст...
Все несколько проще, когда в работе над итоговым текстом участие человека (например, журналиста или писателя) предполагается в принципе.
Итоги:
Whisper работает, и чем лучше запись — тем лучше результат.
Всё работает даже на ноутбуке, которому больше 10 лет, хоть на обработку даже 30-минутного аудио и требуется несколько часов.
Генеративные нейросети могут помочь, а могут и не шибко. Поэтому, пока что — увы: человек, который будет следить, всё ещё нужен: без проверки — нет гарантий хорошего результата.
Но может быть, всё скоро изменится — мир меняется очень быстро.
Посмотрим, что принесёт нам завтра...
p.s. К окончанию написания этой статьи, к примеру, Google уже выдаёт доступы к новому инструменту, который умеет оформлять аудио в текстовый формат, — pinpoint. Вроде работает, но надо тестировать. Если вы журналист, студент или энтузиаст-исследователь — всё в ваших руках!
[декабрь, 2025]




























.jpg)





















.jpg)








































